Drive&Segment: Unsupervised Semantic Segmentation of Urban
Scenes via
Cross-modal Distillation
Abstract
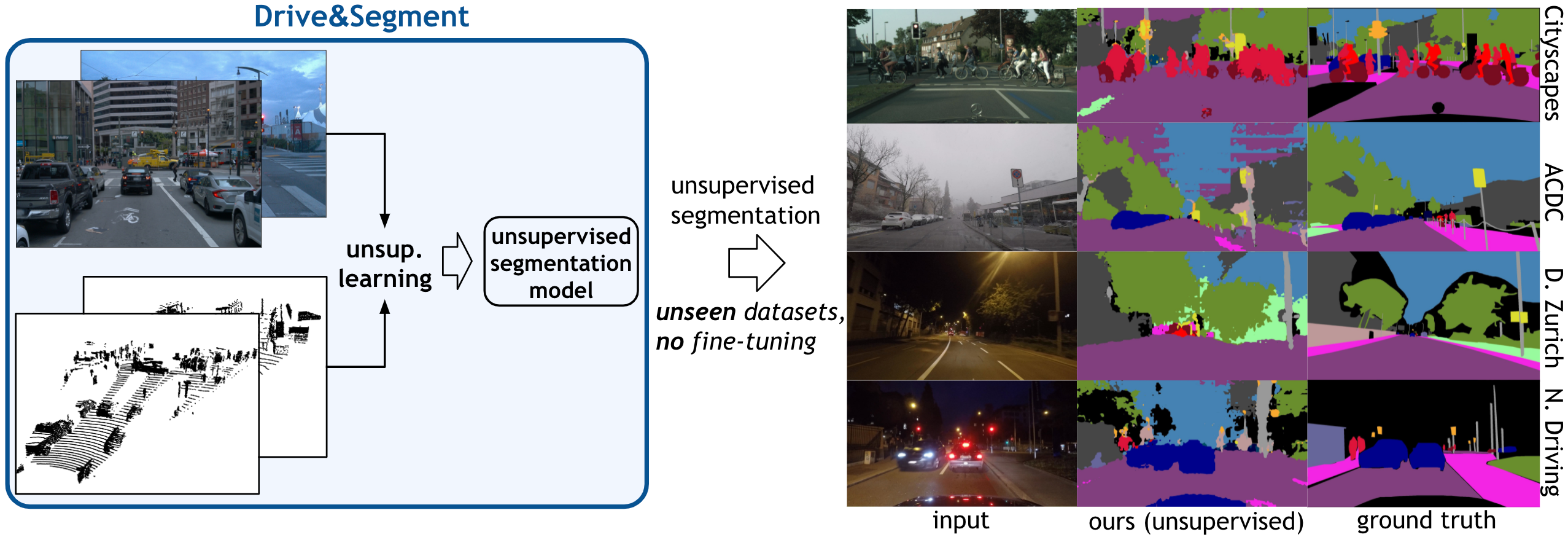
This work investigates learning pixel-wise semantic image segmentation in urban scenes without any manual annotation, just from the raw non-curated data collected by cars which, equipped with cameras and LiDAR sensors, drive around a city. Our contributions are threefold. First, we propose a novel method for cross-modal unsupervised learning of semantic image segmentation by leveraging synchronized LiDAR and image data. The key ingredient of our method is the use of an object proposal module that analyzes the LiDAR point cloud to obtain proposals for spatially consistent objects. Second, we show that these 3D object proposals can be aligned with the input images and reliably clustered into semantically meaningful pseudo-classes. Finally, we develop a cross-modal distillation approach that leverages image data partially annotated with the resulting pseudo-classes to train a transformer-based model for image semantic segmentation. We show the generalization capabilities of our method by testing on four different testing datasets (Cityscapes, Dark Zurich, Nighttime Driving and ACDC) without any finetuning, and demonstrate significant improvements compared to the current state of the art on this problem.
Sample Outputs



Qualitative results. Top: An example of pseudo segmentation, i.e., the output of our method where the classes are not mapped to the target ground-truth classes. Bottom: Two videos from the Cityscapes dataset. To get the pseudo -> ground-truth mapping, we apply the Hungarian algorithm.
Explanatory video
Paper and Supplementary Material
 A. Vobecky, D. Hurych, O. Siméoni, S. Gidaris, A. Bursuc, P. Pérez, and J. Sivic.
A. Vobecky, D. Hurych, O. Siméoni, S. Gidaris, A. Bursuc, P. Pérez, and J. Sivic.Drive&Segment: Unsupervised Semantic Segmentation of Urban Scenes
via Cross-modal Distillation
ArXiv preprint, 2022.
(hosted on ArXiv, full PDF)
@article{vobecky2022drivesegment,
title={Drive&Segment: Unsupervised Semantic Segmentation of Urban Scenes via Cross-modal Distillation},
author={Antonin Vobecky and David Hurych and Oriane Siméoni and Spyros Gidaris and Andrei Bursuc and Patrick Pérez and Josef Sivic},
journal={arXiv preprint arXiv:2203.11160},
year={2022}
}Acknowledgements
This work was partly supported by the European Regional Development Fund under the project IMPACT (reg. no. CZ.02.1.01/0.0/0.0/15_003/0000468), and the Ministry of Education, Youth and Sports of the Czech Republic through the e-INFRA CZ (ID:90140). Antonin Vobecky was supported by CTU Student Grant Agency (reg. no. SGS21/184/OHK3/3T/37).